この記事は CAMPFIRE クラウドファンディング「3Dホログラム・汎用AIアシスタント を普及させたい!」(2024/7/15~8/31)の活動報告の再掲です。
今日は音声対話を実現する「音声認識」についてお話します。
ACUAH は、音声対話型の汎用AIアシスタント を目指して開発をしていますので、音声認識はコアな技術となります。
「音声認識」とは、音(音声)を解析してテキスト文字に変換する技術です。例えば、PCのマイクに向かって「こんにちは」と言葉を発した際に、その音声が解析されて「今日は」というテキスト文字が画面に表示される技術です。
スマートフォンで利用できる音声認識技術には、その解析をスマートフォン内部で行うデバイスローカル版と、インターネット上のサーバーで行うサーバー版があります。
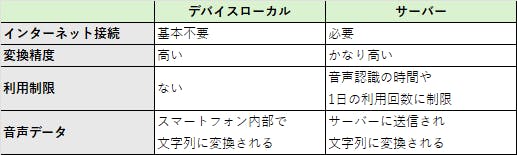
ACUAH は、デバイスローカル版の音声認識を利用しています。
・Android: Android speech recognizer
・iPhone(iOS): SFSpeechRecognizer
と呼ばれる仕組みです。
サーバー版に比べて変換精度は低いですが、
以下の点で本プロジェクト上のメリットが大きいとの判断によるものです。
・利用回数に制限がなく、無料で使える
・音声データがスマートフォン内部で処理されセキュリティ面で安心
ところで、
ACUAH は スマートスピーカーのような
“OK, ○○”、”Hey, ○○”
といったウェイクワードによる音声認識開始の仕組みは採用していません。
キャラクターをタップする事により、音声認識を開始する仕組みとしています。
次回は「ウェイクワード」についてお話できればと思います。