この記事は CAMPFIRE クラウドファンディング「3Dホログラム・汎用AIアシスタント を普及させたい!」(2024/7/15~8/31)の活動報告の再掲です。
音声対話汎用AIアシスタントを作る前提で、 「対話シナリオとAIを組み合わせた仕組み」について書く予定でしたが、
その前に、前回、
「ChatGPTのような昨今のAI(LLM:大規模言語モデル)が救世主に」
と簡単に書いてしまったので、少し補足訂正をさせてください。
まず、現代の(ノイマン型)コンピュータは 「入力」された情報をCPUが何等かの「処理」をして「出力」するものです。
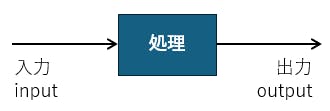
前回の対話シナリオの処理部分を当てはめると、
音声認識で変換された「テキスト文字」が、「対話シナリオ」を使って処理され、対話シナリオに記載された「決まった動作」が実行される
という流れにおいては
・「テキスト文字」が 「入力」(input)
・「対話シナリオ」による処理が 「処理」
・「決まった動作」の実行が 「出力」(output)
となります。
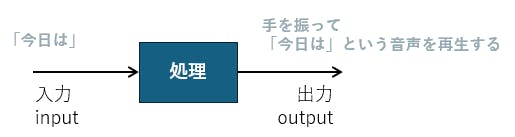
対話シナリオのデメリットは、この「入力」のパターンが沢山ありすぎる場合に、全てに対応する「処理」を書ききれず、処理できないものが発生してしまう、という点になります。
逆に「処理」ができる場合には、確実に決まった動作をさせる事ができます。

一方、
昨今のAI(LLM:大規模言語モデル)のメリットは、「入力」パターンが膨大にあっても、推論「処理」をすることで何等かの「出力」を得る事ができる点にあります。
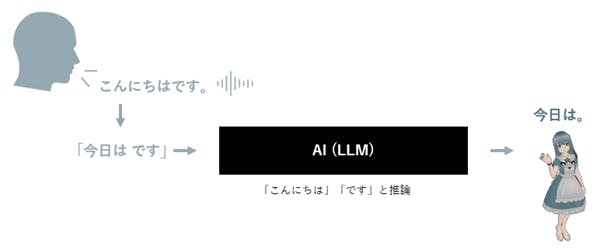
音声対話型の汎用AIアシスタントを作るという前提で、
「ChatGPTのような昨今のAI(LLM:大規模言語モデル)が救世主に」
と書いたものの、この救世主の意図するところは、
あくまでも、昨今のAI(LLM:大規模言語モデル)は
「入力」部分において、膨大にあるパターンに対応できる
という点になります。
次回はAIの出力についてお話させていただく予定です。